Extract, transform, and load (ETL)

From Raw Data to Powerful Insights.
Organizations often struggle with collecting data from multiple sources in various formats and then consolidating it into one or more data stores. The destination may differ from the source in type, format, or structure, requiring data shaping or cleaning before it reaches its final form.
Over the years, numerous tools, services, and processes have been developed to tackle these challenges. Regardless of the chosen approach, there is always a need to coordinate the workflow and apply data transformations within the pipeline. The following sections outline common methods used to achieve these tasks.
Extract, Transform, Load (ETL) is a data pipeline process that gathers data from multiple sources, transforms it according to business requirements, and loads it into a destination data store. The transformation step, which occurs in a specialized engine, often uses staging tables to temporarily hold data as it undergoes operations like filtering, sorting, aggregating, joining, cleaning, deduplication, and validation.
To improve efficiency, ETL phases often run concurrently. For instance, while new data is being extracted, transformation can proceed on already-received data, preparing it for loading, and the loading process can begin on prepared data without waiting for the entire extraction to finish.

Extract, load, transform (ELT)
Extract, Load, Transform (ELT) differs from ETL by where data transformation happens. In ELT, transformation occurs within the target data store, leveraging its processing power and eliminating the need for a separate transformation engine. This simplifies architecture and enhances performance as the target data store scales. ELT is effective for big data scenarios where the target system, such as Hadoop or Azure Synapse, can handle large transformations. Data is extracted to scalable storage like Azure Data Lake and queried directly by technologies such as Spark or Hive. ELT's final phase optimizes data for query efficiency, often using formats like Parquet for fast, columnar storage.
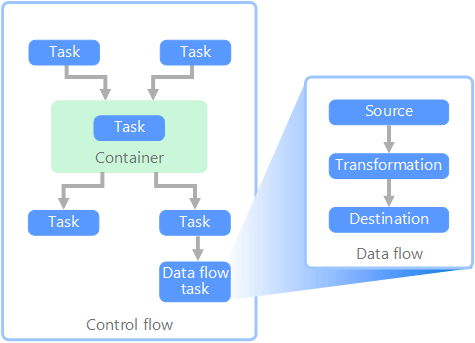
Data flow and control flow
In data pipelines, control flow manages the sequence of tasks, using precedence constraints to ensure tasks are processed in the correct order based on outcomes like success, failure, or completion. Data flow tasks, executed within the control flow, involve extracting, transforming, or loading data. These tasks can run in parallel, passing outputs as inputs between tasks. While control flow allows constraints between tasks, data flow does not, though it supports data viewers to monitor progress. Containers within control flows help structure tasks, especially for repetitive actions, like processing files or database records.